Idiomatic awk


backreference.org
Interests: Regular Expressions, Linux CLI one-liners, Scripting Languages and Vim




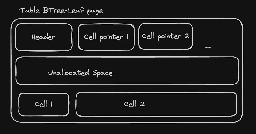






As per the manual, "Mappings are set up to work like most click-and-type editors" - which is best suited with GUI Vim.
While Vim doesn't make sense to use without the modes, there are plugins like https://github.com/tombh/novim-mode!
I start my search string with stackoverflow as a workaround.
oxipng, pngquant and svgcleaner for optimizing images
auto-editor for removing silent portions from video recordings
Hope you find the book useful :)
I'd also suggest these shorter guides to get started:
I use GitHub pages and mdbook (https://github.com/rust-lang/mdBook)
alias a='alias'
a c='clear'
a p='pwd'
a e='exit'
a q='exit'
a h='history | tail -n20'
# turn off history, use 'set -o history' to turn it on again
a so='set +o history'
a b1='cd ../'
a b2='cd ../../'
a b3='cd ../../../'
a b4='cd ../../../../'
a b5='cd ../../../../../'
a ls='ls --color=auto'
a l='ls -ltrhG'
a la='l -A'
a vi='gvim'
a grep='grep --color=auto'
# open and source aliases
a oa='vi ~/.bash_aliases'
a sa='source ~/.bash_aliases'
# sort file/directory sizes in current directory in human readable format
a s='du -sh -- * | sort -h'
# save last command from history to a file
# tip, add a comment to end of command before saving, ex: ls --color=auto # colored ls output
a sl='fc -ln -1 | sed "s/^\s*//" >> ~/.saved_commands.txt'
# short-cut to grep that file
a slg='< ~/.saved_commands.txt grep'
# change ascii alphabets to unicode bold characters
a ascii2bold="perl -Mopen=locale -Mutf8 -pe 'tr/a-zA-Z/𝗮-𝘇𝗔-𝗭/'"
### functions
# 'command help' for command name and single option - ex: ch ls -A
# see https://github.com/learnbyexample/command_help for a better script version
ch() { whatis $1; man $1 | sed -n "/^\s*$2/,/^$/p" ; }
# add path to filename(s)
# usage: ap file1 file2 etc
ap() { for f in "$@"; do echo "$PWD/$f"; done; }
# simple case-insensitive file search based on name
# usage: fs name
# remove '-type f' if you want to match directories as well
fs() { find -type f -iname '*'"$1"'*' ; }
# open files with default application, don't print output/error messages
# useful for opening docs, pdfs, images, etc from command line
o() { xdg-open "$@" &> /dev/null ; }
# if unix2dos and dos2unix commands aren't available by default
unix2dos() { sed -i 's/$/\r/' "$@" ; }
dos2unix() { sed -i 's/\r$//' "$@" ; }
EPUB reader
Check out https://github.com/auctors/free-lunch (list of free Windows software)
See also https://www.nirsoft.net/ (freeware, not open source)
Here are some resources that might help:
For scripting, keep these links handy:
Also, +1 for Linux Journey mentioned in another comment.
https://github.com/WyattBlue/auto-editor - automatically editing video and audio by analyzing a variety of methods, most notably audio loudness
https://github.com/shssoichiro/oxipng, https://pngquant.org/ and https://github.com/RazrFalcon/svgcleaner for optimizing images
I have a book for Perl One-Liners as well, which I'm currently revising :)
I had to learn Linux CLI tools, Vim and Perl at my very first job. Have a soft spot for Perl, despite not using it much these days other than occasional one-liners (mainly for advanced regex features).
I've written books on regex too, if you are interested in learning ;)
See also: https://github.com/pllk/cphb (Competitive Programmer's Handbook)
Yeah, it is uncommon spelling, but if you google, you'll find it's not that rare ;)
Inspired by explainshell, I wrote a script (https://github.com/learnbyexample/command_help) to be used from the terminal itself. It is a bit buggy, but works well most of the time. For example:
$ ch grep -Ao
grep - print lines that match patterns
-A NUM, --after-context=NUM
Print NUM lines of trailing context after matching lines. Places a
line containing a group separator (--) between contiguous groups of
matches. With the -o or --only-matching option, this has no effect
and a warning is given.
-o, --only-matching
Print only the matched (non-empty) parts of a matching line, with
each such part on a separate output line.
You can do it in Bash as well. Put this in .inputrc:
"\e[A":history-substring-search-backward
"\e[B":history-substring-search-forward
# or, if you want to search only from the start of the command
"\e[A": history-search-backward
"\e[B": history-search-forward
Thanks a lot for the feedback on Coreutils book! It's so nice to hear that it helped in your thesis.
Regarding the ebook versions, I use pandoc to convert GitHub style Markdown to PDF/EPUB (wrote a blog post about my process here: https://learnbyexample.github.io/customizing-pandoc/). I had to search through stackexchange threads to customize the few things I could. I don't know how to fix the kind of page breaks you mentioned. But, I'll try to find a solution. Thanks again for the feedback :)
Thanks a lot for the kind words! Means a lot to me :)
I'm self-published and haven't worked for other publications. Sometimes, my submissions reach HN front page, so you might have seen there or because others picked it up from there and shared around elsewhere.
Check out https://novelwriter.io/
I'm not familiar with such softwares (I use pandoc for technical writing), but might help you..
Is it regex or sed/awk syntax (or both) that gives you trouble?
I had similar reaction and didn't even try to learn them for years - then I caught the stackoverflow craze of answering CLI questions (and learning from others).
That depends on the regex flavor. Some of them have full support for variable length lookbehinds, for example JavaScript and third-party regex module for Python.
Thanks! 😊
Not my blog, just sharing it here. Saw it on HN (https://news.ycombinator.com/item?id=40419325)
That's great to hear and thanks for the kind feedback :)
I use GVim for coding and text editing in general.
Programming wise, CLI tools (grep, sed, awk, sort, head, etc) are enough for most of my tasks. I've written a few Python TUI projects (uses Textual framework) but these are around 300-400 lines, so Vim is more than enough for my purposes. Don't even need any plugins.
You're welcome, happy learning :)
I have a list of learning resources for CLI tools and scripting here: https://learnbyexample.github.io/curated_resources/linux_cli_scripting.html
I've also written a few TUI interactive apps to practice text processing commands like grep, sed, awk, coreutils, etc: https://github.com/learnbyexample/TUI-apps
I have a concise guide at https://learnbyexample.github.io/cli-computing/searching-files-and-filenames.html#grep and a more detailed book at https://learnbyexample.github.io/learn_gnugrep_ripgrep/introduction.html. Both have examples and exercises.
The post isn't about terminal frameworks though, it is about how to get started using the command line.
I used to use it for posting on Twitter, with some keywords (like book title) in bold.
What's the difference between two_percent and skim?
Not my blog, just sharing it here.
That said, I don't see that broken rectangle on Chromium.
Why do you think it is a phishing link? Gumroad is a well known platform to sell digital goods.
I mention it is free up to some date because it will go back to being a paid product after that.
Can't reproduce your issue:
$ line='2023-06-19T00:00:00+01:00 2023-06-18T00:00:00+01:00 2023-06-17T00:00:00+01:00 2023-06-16T00:00:00+01:00 2023-06-15T00:00:00+01:00 2023-06-14T00:00:00+01:00 2023-06-13T00:00:00+01:00 2023-06-10T00:00:00+01:00 2023-06-03T00:00:00+01:00 2023-05-31T00:00:00+01:00 2023-05-27T00:00:00+01:00'
$ arr=( $line )
$ echo "${arr[4]}"
2023-06-15T00:00:00+01:00
See also: