The Linux kernel has been accidentally hardcoded to a maximum of 8 cores for nearly 20 years

thehftguy.com
I'm not smart enough to verify the accuracy of this claim, nor exactly what the implications are, but it seems like it might improve performance if fixed.
Title bullshit, we have multicore machine for years, I can guarantee you this had about no impact else people running Xeon or Threadripper would have saw it at first try 15 years ago.
This looks like to have an impact on the scheduler but not on how many cores are used.
I agree. Some of the Linux servers I used to run at work in the early 00's were 12 to 16 core monsters (for the time) and the kernel didn't even blink.
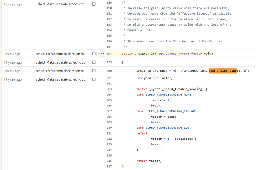
There's a variable that contains the number of cores (called
cpus) which is hardcoded to max out at 8, but it doesn't mean that cores aren't utilized beyond 8 cores--it just means that the scheduling scaling factor will not change in either the linear or logarithmic case once you go above that number:::: spoiler code snippet
:::
The core claim is this:
On this point, I have no idea (hope someone more knowledgeable will weigh in). But I'd say the headline is misleading at best.
I took the title from the link, which doesn't exactly match the title on the page. That's why one says 20 years and the other says 15 years.
Heard of that, because you know, a core Duo was a thing. They didnt think anything bigger was possible, some time in the past. But afaik thats pretty old news
Would've been nice of them to compile the kernel with a fix applied to see how much of an impact it has (though even in the post they seem to suggest that it's not that impactful unless you run massive clusters)