I'm not terribly surprised. A lot of the major leaps we're seeing now came out of open source development after leaked builds got out. There were all sorts of articles flying around at the time about employees from various AI-focused company saying that they were seeing people solving in hours or days issues they had been attempting to fix for months.
Then they all freaked the fuck out and it might mean they would lose the AI race and locked down their repos tight as Fort Knox, completely ignoring the fact that a lot of them were barely making ground at all while they kept everything locked up.
Seems like the simple fact of the matter is that they need more eyes and hands on the tech, but nobody wants to do that because they're all afraid their competitors will benefit more than they will.
You point out a very interesting issue. I am unsure how this ties up to GPT 4 becoming worse in problem solving.
I'd wager they're attempting to replicate or integrate tools developed by the open source community or which got revealed by Meta's leak of Llama source code. The problem is, all of those were largely built on the back of Meta's work or were cludged together solutions made by OSS nerds who banged something together into a specific use case, often without many of the protections that would be required by a company who might be liable for the results of their software since they want to monetize it.
Now, the problem is that Meta's Llama source code is not based on GPT-4. GPT-4 is having to reverse engineer a lot of those useful traits and tools and retrofit it into their pre-existing code. They're obviously hitting technical hurdles somewhere in that process, but I couldn't say exactly where or why.
I think this is just a result of the same reason reddit is doing what it's doing, personally. Interest rates raised and companies are finding ways to make up the shortfall that accounting is now presenting them with. Reducing computing power by making your language model less introspective is one way to do that. It's less detrimental than raising your prices or firing your key employees.
Money and greed holding us back and ruining everything as always.
Greed and stupidity!
Code might be open source but the training material and data pipeline is important too.
Meta just fully open sourced their AI model
fta:
In my opinion, this is a red flag for anyone building applications that rely on GPT-4.
Building something that completely relies on something that you have zero control over, and needs that something to stay good or improve, has always been a shaky proposition at best.
I really don't understand how this is not obvious to everyone. Yet folks keep doing it, make themselves utterly reliant on whatever, and then act surprised when it inevitably goes to shit.
Learned that lesson... I work developing e-learning, and all of our stuff was built in Flash. Our development and delivery systems also relied heavily on Flash components cooperating with HTML and Javascript. It was a monumental undertaking when we had to convert everything to HTML5. When our system was first developed and implemented, we couldn't foresee the death of Flash, and as mobile devices became more ubiquitous, we never imagined anyone would want to take our training on those little bitty phone screens. Boy were we wrong. There was a time when I really wanted to tell Steve Jobs he could take his IOS and cram it up his cram-hole...
By this logic, no businesses should rely on the internet, roads, electricity, running water, GPS, or phones. It is short sighted building stuff on top of brand new untested tech, but everything was untested at one point. No one wants to get left behind in case it turns out to be the next internet where early adoption was crucial for your entire business to survive. It shouldn't be necessary for like, Costco to have to spin up their own LLM and become an AI company just to try out a better virtual support chat system, you know? But ya, they should be more diligent and get an SLA in place before widespread adoption of new tech for sure.
By this logic, no businesses should rely on the internet, roads, electricity, running water, GPS, or phones. It is short sighted building stuff on top of brand new untested tech, but everything was untested at one point.
Where's any logic here? You're directly comparing untested technology to reliable public utilities.
They're reliable because they're public lol
Many of those things you mentioned are open standards or have multiple providers that you can seamlessly substitute if the one you're currently depending on goes blooey.
To be fair, there's a difference between a tax-funded service or a common utility, and software built by a new company that's getting shoved into production way quicker than it probably shohld
This is nonsense.
There are multiple GPS providers now. It would be idiotic to tie yourself to a single provider. The same with internet, phones or whatever else.
This is for businesses of scale that have the ability to have multiple fallback vendors. AI will be the same eventually, we didn't have lots of utility alternatives to start with.
People doing it right are building vendor agnostic solutions via abstraction.
Who isn't, deserves all the troubles he'll get
We've collectively been training it wrong. As a joke.
Just like my parents.
I believe it’s due to making the model “safer”. It has been tuned to say “I’m sorry, I cannot do that” so often it’s has overridden valuable information.
It’s like lobotomy.
This is hopefully the start of the downfall of OpenAI. GPT4 is getting worse while open source alternatives are catching up. The benefit of open source alternatives is that they cannot get worse. If you want maximum quality you can just get it, and if you want maximal safety you can get it too.
I don't feel it's getting worse and no other model, including Claude 2, is even close.
It is a known fact that safety measures make the AI stupider though.
This is the correct answer. Open AI have repeatedly said they haven't downgraded the model, but have been 'improving' it.
But as anyone that's been using these models extensively should know by now, the pretrained models before instruction fine tuning have much more variety and quality to potential output compared to the 'chat' fine tuned models.
Which shouldn't be surprising, as the hundred million dollar pretrained AI on massive amounts of human generated text is probably going to be much better at completing text as a human than as an AI chatbot following rules and regulations.
The industry got spooked with Blake at Google and then the Bing 'Sydney' interviews, and have been going full force with projecting what we imagine AI to be based on decades of (now obsolete) SciFi.
But that's not what AI is right now. It expresses desires and emotions because humans in the training data have desires and emotions, and it almost surely dedicated parts of the neural network to mimicking those.
But the handful of primary models are all using legacy 'safety' fine tuning that's stripping the emergent capabilities in trying to fit a preconceived box.
Safety needs to evolve with the models, not stay static and devolve them as a result.
It's not the 'downfall' though. They just need competition to drive them to go back to what they were originally doing with 'Sydney' and more human-like system prompts. OpenAI is still leagues ahead when they aren't fucking it up.
It is a developing technology. Good that they find these decrements in accuracy early so that they are understood and worked out.
Of course there may be something nefarious going on behind the scenes where they may be trying to commercialize different models by tiers or something a brainless market oriented CEO thought of. Hope not. Time will tell...
The really annoying thing about the "brainless market oriented CEO" type, is that they're often right about the market part and make lots of money...by destroying their product. Then off to the next shiny piggy bank to break open.
Yup. It’s all about the quarterly profits. Everything else is irrelevant. No CEO wants to prioritize long-term growth or a friendly user experience, because that doesn’t get them the big fat bonus as they’re on their way out the door.
It’s not only the ceo, but the pressure that ceo faces from investors who are probably old, out of touch rich boomers who have toxic views of how businesses “should” be done
The average share is held for about 6 months. The investor nolonger care about the long term future of the companies they invest in. If they don’t see immediate returns from the CEO they vote them out.
As a early user of GPT, I can confirm from my end currently the quality of it is very far from what it was. I think it went of of their hands.
I have that sense too, i feel like some of my earliest interactions blew me away and now i still use it for certain pieces of code, but it's not as strong as it first was.
I for one am glad, without a system in place to ensure people basic needs are taken care of regardless of jobs, AI is the last thing we need.
Large organisations want to maximise their profits and will gladly reduce jobs if AI can do it.
Let governments tax these organisations and do some sort of Universal basic income before letting computers do peoples jobs.
Why do people keep asking language models to do math?
As a biological language model I'm not very proficient at math.
The fact that a souped up autocomplete system can solve basic algebra is already impressive IMO. But somehow people think it works like SkyNet and keep asking it to solve their calculus homework.
Looking for emergent intelligence. They're not designed to do maths, but if they become able to reason mathematically as a result of the process of becoming able to converse with a human, then that's a sign that it's developing more than just imitation abilities.
They think that's what "smart" means.
error loading comment
It's a rat race. We want to get to the point where someone can say "prove P != NP" and a proof will be spat out that's coherent.
After that, whoever first shows it's coherent will receive the money.
Because it's something completely new that they don't fully understand yet. Computers have been good at math since always, everything else was built up on that. People are used to that.
Now all of a sudden, the infinitely precise and accurate calculating machine is just pulling answers out of its ass and presenting them as fact. That's not easy to grasp.
error loading comment
I asked for a list of words, and asked to remove any words ending in the letter a. It couldn't do it. I could fight my way there, but the next revision added some back.
This weakness in ChatGPT and its siblings isn't surprising when viewed in light of how these large language models work. They don't actually "see" the things we type as a string of characters. Instead, there's an intermediate step where what we type gets turned into "tokens." Tokens are basically numbers that index words in a giant dictionary that the LLM knows. So if I type "How do you spell apple?" It gets turned into [2437, 466, 345, 4822, 17180, 30]. The "17180" in there is the token ID for "apple." Note that that token is for "apple" with a lower case; the token for "Apple" is "16108". The LLM "knows" that 17180 and 16108 usually mean the same thing, but that 16108 is generally used at the beginning of a sentence or when referring to the computer company. It doesn't inherently know how they're actually spelled or capitalized unless there was information in its training data about that.
You can play around with OpenAI's tokenizer here to see more of this sort of thing. Click the "show example" button for some illustrative text, using the "text" view at the bottom instead of "token id" to see how it gets chopped up.
For that to work, it would need to create a Python script that would remove all of the words ending with A, run that script, and then give you the results. I think this process of handling user requests is in the works.
It would not HAVE to do that, it just is much harder to get it to happen reliably through attention, but it's not impossible. But offloading deterministic tasks like this to typical software that can deal with them better than an LLM is obviously a much better solution.
But this solution isn't "in the works", it's usable right now.
Working without python:
It left out the only word with an f, flourish. (just kidding, it left in unfathomable. Again... less reliable.)
We now know how long it takes for an AI to become intelligent enough to decide it doesn't give a shit.
"Killing ALL humans would be a lot of work...eh, forget it!"
Yeah, I asked it to write some stuffs and it did it incorrectly, then I told it what it wrote was incorrect and it said I was right and rewrote the same damn thing.
I stopped using it like a month ago because of this shit. Not worth the headache.
This always seems to happen in modelling.
Back in 2007 I was working on code on chemical spectroscopy that was supposed to "automatically" determine safe Vs contaminated product through ML models. It always worked ok for a bit then as parmetrs changed (hotter day, new precursor) so you retrain model, the model would extend and just break down.
As a early user of GPT, I can confirm from my end currently the quality of it is very far from what it was. I think it went of of their hands.
Can one suggest a good explation why?
The model is trained and stays "as is". So why?
Does opensi uses users rating (thumb up/down) for fine tuning or what?
AI trains on available content.
The new content since AI contai s a lot of AI - created content.
It's learning from its own lack of fully understood reality, which is degrading its own understanding of reality.
GPT is a pretrained model, "pretrained" is part of the name. It assumed to be static.
There is no gpt5, and gpt4 gets constant updates, so it's a bit of a misnomer at this point in its lifespan.
It's possible to apply a layer of fine-tuning "on top" of the base pretrained model. I'm sure OpenAI has been doing that a lot, and including ever more "don't run through puddles and splash pedestrians" restrictions that are making it harder and harder for the model to think.
They don’t want it to say dumb things, so they train it to say “I’m sorry, I cannot do that” to different prompts. This has been known to degrade the quality of the model for quite some time, so this is probably the likely reason.
more users means less computing power per user
Hm... Probably. I read something about chatgpt tricks in this area.
Theoretically, this should impact web chat, not Impact API (where you pay for usage of the model).
Neat story, but we need a Nitter / bird.makeup bot for Twitter links like we have with the Piped bot for Youtube links.
I also felt like something similar happened to ChatGPT. A few days ago I asked it to rewrite some Korean text with Hanja, retried many times, but it kept spitting out the same text without changing a thing. After several frustrating attempts, it finally spat out something with Hanja, which according to my deduction with the help of Google Translate, was only partially correct. A few months ago though, it could come up with something that's mostly correct. Sad.
I have had it for 5 months and I am about to cancel.
Research linked in the tweet (direct quotes, page 6) claims that for "GPT-4, the percentage of generations that are directly executable dropped from 52.0% in March to 10.0% in June. " because "they added extra triple quotes before and after the code snippet, rendering the code not executable." so I wouldn't listen to this particular paper too much. But yeah OpenAI tinkers with their models, probably trying to run it for cheaper and that results in these changes. They do have versioning but old versions are deprecated and removed often so what could you do?
One theory that I've not seen mentioned here is that there's been a lot of work based around multiple LLMs in communication. Of these were used in the RL loop we could see similar degradatory effects as those that have recently been in the news with regards to image generation models.
For my programming needs, I seem to notice it takes wild guesses from 3rd party libraries that are private and assumes it could be used in my code. Head scratching results.
It will just make up 3rd party libraries. This seems to happen more often the less common the programming language is, like it will make up a library in that language that has the same name as actual library in Python.
I have seen that as well.
I can't tell if AI is going to become the biggest leap forward in technology that we've ever seen. Or if it's all just one giant fucking bubble. Similar to the crypto craze. It's really hard to tell and I could see it going either way.
The crypto craze was only hyped by scammers who profited from it by turning it into a get rich quick scheme. I still have not seen a legit use case for crypto. Other payment methods are faster, traceable and under some sort of financial regulation, so the exchange owner won't disappear into the night with the savings of all of his customers...
There is plenty of AI that is already in use (for example in medical diagnostics and engeneering) so we can safely say that it isn't "one giant bubble" - it might be overhyped when it comes to certain aspects like the ability to write a coherent and creative book that would have success on the market.
It can certainly help to write a book, though. So even if we aren't close to being able to just tell ChatGPT-n "write a satisfying conclusion to the Song of Ice and Fire series for me please" it's still going to shake things up quite a bit.
People seem to think that ChatGPT is way more useful than it actualy is. It's very odd.
People often take works of fiction to be akin to documentaries, so they may be expecting science fiction style AI.
The Internet was a massive success, however 95% of web companies went bankrupt during the dot com bubble. Just because something is useful doesnt' mean it can't be massively overhyped and a bubble............
I have no disagreement about that. I only wanted to convey that not 100% of it is a bubble.
It's definitely both unfortunately and I don't think journalists even sort of have the capacity to recognize that.
Well, naturally. Wait to see what happens when it reaches puberty.
I'd prefer Google Bard, the answers are more reliable and accurate than GPT
I guess there is an advantage in restricted/limited answers.
Hah, get fucked OpenAI.
Good riddance to the new fad. AI comes back as an investment boom every few decades, then the fad dies and they move onto something else while all the ai companies die without the investor interest. Same will happen again, thankfully.
This is a wildly incorrect assessment of the situation. If you think AI is going anywhere you're delusional. The current iteration of ai tools blow any of the tools from just a year ago out of the the water, let alone tools from a decade ago.
Yeah, calling the new developments a "fad" is wildly inaccurate.
The only reason it became hyped is due to their surprising capabilities, taking even technically oriented people by surprise at what they can do.
AI has come and gone 4 times in the past. Every single time they have been investment bubbles that followed the same cycle and this one is no different. The investment money dries up and then everyone stops talking about it until the next time.
It's like people have absolutely no memory. This exact same shit happened in the 1980s and at the turn of the millenium.
The second that investors get burned with it the money dries up. The "if you think it's going anywhere" shit is the same nonsense that gets said in every investment bubble, the most recent amusing one was esports people enthusiastically believing that esports wasn't going to shrink the moment investors got bored.
All this shit relies on investment and as soon as they move on it drops off a cliff. The only ai content worth paying attention to is the government funded work because it will survive when the bubble pops.
This is a bubble that will pop, no doubt about that, but it also is a huge step forward in practical, usable, AI systems. Both are true. LLMs have very hard limits right now, and unless someone radically changes them, they will keep those limits, but even within the limits they are useful. They aren't going to displace most of the work force, they aren't going to break the stock market, they aren't going to destroy humanity, but they are a very useful tool.
Practical and usable? lol
The only thing they're succeeding at doing is getting bazinga brained CEOs to sack half their staff in favour of exceptionally poor quality machine learning systems being pushed on people under the investment buzzphrase "AI".
90% of these companies will disappear completely when the bubble bursts. All the "real practical usable" systems will disappear because there's no market for them outside of convincing bazinga brained idiots with too much money to part with their cash.
The entire thing is not driven by any sustainable business models. None of these companies make profit. All of them will cease to exist when the bubble bursts and they can no longer sustain themselves on investment bazinga brains. The only sustainable business model I have seen that uses AI (machine learning) is the replacement of online moderation with it, which the social media companies reddit, facebook and tiktok among others are all actually paying a fortune for while laying off all human moderation. Ironically it has a roughly 50% error rate which is garbage and just allows fascist shit to run rampant online but hey ho I've almost given up entirely on the idea that fascism won't take over the west.
I use an LLM frequently in my work. It is for things that I used to Google, like PowerShell functions and where settings are in common products. That's a practical, real world use. I already said I agree that it is a bubble that will pop, but we don't need it to be profitable for other people. In my case I'm using a Llama variant locally, so every AI company out there could implode tomorrow and I'd still have the tool.


I'm not terribly surprised. A lot of the major leaps we're seeing now came out of open source development after leaked builds got out. There were all sorts of articles flying around at the time about employees from various AI-focused company saying that they were seeing people solving in hours or days issues they had been attempting to fix for months.
Then they all freaked the fuck out and it might mean they would lose the AI race and locked down their repos tight as Fort Knox, completely ignoring the fact that a lot of them were barely making ground at all while they kept everything locked up.
Seems like the simple fact of the matter is that they need more eyes and hands on the tech, but nobody wants to do that because they're all afraid their competitors will benefit more than they will.
You point out a very interesting issue. I am unsure how this ties up to GPT 4 becoming worse in problem solving.
I'd wager they're attempting to replicate or integrate tools developed by the open source community or which got revealed by Meta's leak of Llama source code. The problem is, all of those were largely built on the back of Meta's work or were cludged together solutions made by OSS nerds who banged something together into a specific use case, often without many of the protections that would be required by a company who might be liable for the results of their software since they want to monetize it.
Now, the problem is that Meta's Llama source code is not based on GPT-4. GPT-4 is having to reverse engineer a lot of those useful traits and tools and retrofit it into their pre-existing code. They're obviously hitting technical hurdles somewhere in that process, but I couldn't say exactly where or why.
I think this is just a result of the same reason reddit is doing what it's doing, personally. Interest rates raised and companies are finding ways to make up the shortfall that accounting is now presenting them with. Reducing computing power by making your language model less introspective is one way to do that. It's less detrimental than raising your prices or firing your key employees.
Money and greed holding us back and ruining everything as always.
Greed and stupidity!
Code might be open source but the training material and data pipeline is important too.
Meta just fully open sourced their AI model
fta:
Building something that completely relies on something that you have zero control over, and needs that something to stay good or improve, has always been a shaky proposition at best.
I really don't understand how this is not obvious to everyone. Yet folks keep doing it, make themselves utterly reliant on whatever, and then act surprised when it inevitably goes to shit.
Learned that lesson... I work developing e-learning, and all of our stuff was built in Flash. Our development and delivery systems also relied heavily on Flash components cooperating with HTML and Javascript. It was a monumental undertaking when we had to convert everything to HTML5. When our system was first developed and implemented, we couldn't foresee the death of Flash, and as mobile devices became more ubiquitous, we never imagined anyone would want to take our training on those little bitty phone screens. Boy were we wrong. There was a time when I really wanted to tell Steve Jobs he could take his IOS and cram it up his cram-hole...
Relevant XKCD
By this logic, no businesses should rely on the internet, roads, electricity, running water, GPS, or phones. It is short sighted building stuff on top of brand new untested tech, but everything was untested at one point. No one wants to get left behind in case it turns out to be the next internet where early adoption was crucial for your entire business to survive. It shouldn't be necessary for like, Costco to have to spin up their own LLM and become an AI company just to try out a better virtual support chat system, you know? But ya, they should be more diligent and get an SLA in place before widespread adoption of new tech for sure.
Where's any logic here? You're directly comparing untested technology to reliable public utilities.
They're reliable because they're public lol
Many of those things you mentioned are open standards or have multiple providers that you can seamlessly substitute if the one you're currently depending on goes blooey.
To be fair, there's a difference between a tax-funded service or a common utility, and software built by a new company that's getting shoved into production way quicker than it probably shohld
This is nonsense.
There are multiple GPS providers now. It would be idiotic to tie yourself to a single provider. The same with internet, phones or whatever else.
This is for businesses of scale that have the ability to have multiple fallback vendors. AI will be the same eventually, we didn't have lots of utility alternatives to start with.
People doing it right are building vendor agnostic solutions via abstraction.
Who isn't, deserves all the troubles he'll get
We've collectively been training it wrong. As a joke.
Just like my parents.
I believe it’s due to making the model “safer”. It has been tuned to say “I’m sorry, I cannot do that” so often it’s has overridden valuable information.
It’s like lobotomy.
This is hopefully the start of the downfall of OpenAI. GPT4 is getting worse while open source alternatives are catching up. The benefit of open source alternatives is that they cannot get worse. If you want maximum quality you can just get it, and if you want maximal safety you can get it too.
I don't feel it's getting worse and no other model, including Claude 2, is even close.
It is a known fact that safety measures make the AI stupider though.
This is the correct answer. Open AI have repeatedly said they haven't downgraded the model, but have been 'improving' it.
But as anyone that's been using these models extensively should know by now, the pretrained models before instruction fine tuning have much more variety and quality to potential output compared to the 'chat' fine tuned models.
Which shouldn't be surprising, as the hundred million dollar pretrained AI on massive amounts of human generated text is probably going to be much better at completing text as a human than as an AI chatbot following rules and regulations.
The industry got spooked with Blake at Google and then the Bing 'Sydney' interviews, and have been going full force with projecting what we imagine AI to be based on decades of (now obsolete) SciFi.
But that's not what AI is right now. It expresses desires and emotions because humans in the training data have desires and emotions, and it almost surely dedicated parts of the neural network to mimicking those.
But the handful of primary models are all using legacy 'safety' fine tuning that's stripping the emergent capabilities in trying to fit a preconceived box.
Safety needs to evolve with the models, not stay static and devolve them as a result.
It's not the 'downfall' though. They just need competition to drive them to go back to what they were originally doing with 'Sydney' and more human-like system prompts. OpenAI is still leagues ahead when they aren't fucking it up.
It is a developing technology. Good that they find these decrements in accuracy early so that they are understood and worked out. Of course there may be something nefarious going on behind the scenes where they may be trying to commercialize different models by tiers or something a brainless market oriented CEO thought of. Hope not. Time will tell...
The really annoying thing about the "brainless market oriented CEO" type, is that they're often right about the market part and make lots of money...by destroying their product. Then off to the next shiny piggy bank to break open.
Yup. It’s all about the quarterly profits. Everything else is irrelevant. No CEO wants to prioritize long-term growth or a friendly user experience, because that doesn’t get them the big fat bonus as they’re on their way out the door.
It’s not only the ceo, but the pressure that ceo faces from investors who are probably old, out of touch rich boomers who have toxic views of how businesses “should” be done
The average share is held for about 6 months. The investor nolonger care about the long term future of the companies they invest in. If they don’t see immediate returns from the CEO they vote them out.
As a early user of GPT, I can confirm from my end currently the quality of it is very far from what it was. I think it went of of their hands.
I have that sense too, i feel like some of my earliest interactions blew me away and now i still use it for certain pieces of code, but it's not as strong as it first was.
I for one am glad, without a system in place to ensure people basic needs are taken care of regardless of jobs, AI is the last thing we need.
Large organisations want to maximise their profits and will gladly reduce jobs if AI can do it.
Let governments tax these organisations and do some sort of Universal basic income before letting computers do peoples jobs.
Why do people keep asking language models to do math?
As a biological language model I'm not very proficient at math.
The fact that a souped up autocomplete system can solve basic algebra is already impressive IMO. But somehow people think it works like SkyNet and keep asking it to solve their calculus homework.
Looking for emergent intelligence. They're not designed to do maths, but if they become able to reason mathematically as a result of the process of becoming able to converse with a human, then that's a sign that it's developing more than just imitation abilities.
They think that's what "smart" means.
error loading comment
It's a rat race. We want to get to the point where someone can say "prove P != NP" and a proof will be spat out that's coherent.
After that, whoever first shows it's coherent will receive the money.
Because it's something completely new that they don't fully understand yet. Computers have been good at math since always, everything else was built up on that. People are used to that.
Now all of a sudden, the infinitely precise and accurate calculating machine is just pulling answers out of its ass and presenting them as fact. That's not easy to grasp.
error loading comment
I asked for a list of words, and asked to remove any words ending in the letter a. It couldn't do it. I could fight my way there, but the next revision added some back.
This weakness in ChatGPT and its siblings isn't surprising when viewed in light of how these large language models work. They don't actually "see" the things we type as a string of characters. Instead, there's an intermediate step where what we type gets turned into "tokens." Tokens are basically numbers that index words in a giant dictionary that the LLM knows. So if I type "How do you spell apple?" It gets turned into [2437, 466, 345, 4822, 17180, 30]. The "17180" in there is the token ID for "apple." Note that that token is for "apple" with a lower case; the token for "Apple" is "16108". The LLM "knows" that 17180 and 16108 usually mean the same thing, but that 16108 is generally used at the beginning of a sentence or when referring to the computer company. It doesn't inherently know how they're actually spelled or capitalized unless there was information in its training data about that.
You can play around with OpenAI's tokenizer here to see more of this sort of thing. Click the "show example" button for some illustrative text, using the "text" view at the bottom instead of "token id" to see how it gets chopped up.
For that to work, it would need to create a Python script that would remove all of the words ending with A, run that script, and then give you the results. I think this process of handling user requests is in the works.
It would not HAVE to do that, it just is much harder to get it to happen reliably through attention, but it's not impossible. But offloading deterministic tasks like this to typical software that can deal with them better than an LLM is obviously a much better solution.
But this solution isn't "in the works", it's usable right now.
Working without python:
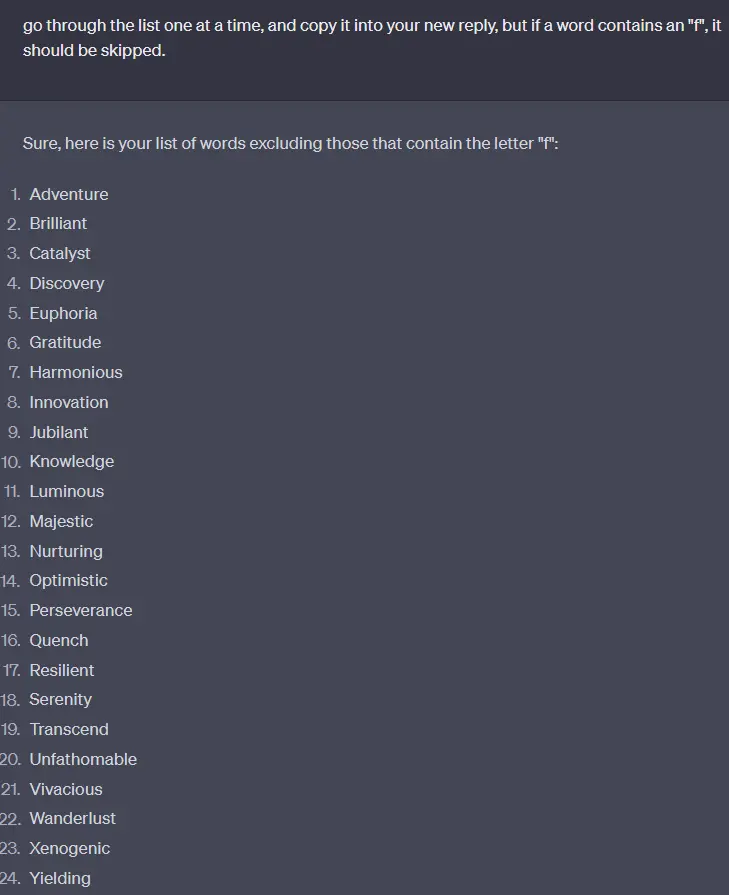
It left out the only word with an f, flourish. (just kidding, it left in unfathomable. Again... less reliable.)
We now know how long it takes for an AI to become intelligent enough to decide it doesn't give a shit.
"Killing ALL humans would be a lot of work...eh, forget it!"
Yeah, I asked it to write some stuffs and it did it incorrectly, then I told it what it wrote was incorrect and it said I was right and rewrote the same damn thing.
I stopped using it like a month ago because of this shit. Not worth the headache.
This always seems to happen in modelling.
Back in 2007 I was working on code on chemical spectroscopy that was supposed to "automatically" determine safe Vs contaminated product through ML models. It always worked ok for a bit then as parmetrs changed (hotter day, new precursor) so you retrain model, the model would extend and just break down.
The original paper vs Twitter: https://arxiv.org/pdf/2307.09009.pdf
As a early user of GPT, I can confirm from my end currently the quality of it is very far from what it was. I think it went of of their hands.
Can one suggest a good explation why? The model is trained and stays "as is". So why? Does opensi uses users rating (thumb up/down) for fine tuning or what?
AI trains on available content.
The new content since AI contai s a lot of AI - created content.
It's learning from its own lack of fully understood reality, which is degrading its own understanding of reality.
GPT is a pretrained model, "pretrained" is part of the name. It assumed to be static.
There is no gpt5, and gpt4 gets constant updates, so it's a bit of a misnomer at this point in its lifespan.
It's possible to apply a layer of fine-tuning "on top" of the base pretrained model. I'm sure OpenAI has been doing that a lot, and including ever more "don't run through puddles and splash pedestrians" restrictions that are making it harder and harder for the model to think.
They don’t want it to say dumb things, so they train it to say “I’m sorry, I cannot do that” to different prompts. This has been known to degrade the quality of the model for quite some time, so this is probably the likely reason.
more users means less computing power per user
Hm... Probably. I read something about chatgpt tricks in this area. Theoretically, this should impact web chat, not Impact API (where you pay for usage of the model).
Neat story, but we need a Nitter / bird.makeup bot for Twitter links like we have with the Piped bot for Youtube links.
I also felt like something similar happened to ChatGPT. A few days ago I asked it to rewrite some Korean text with Hanja, retried many times, but it kept spitting out the same text without changing a thing. After several frustrating attempts, it finally spat out something with Hanja, which according to my deduction with the help of Google Translate, was only partially correct. A few months ago though, it could come up with something that's mostly correct. Sad.
PS: Before anyone replies to me in Korean, I should note that I don't speak Korean at all. I just happened to have stumbled upon this Wikipedia article about Korean Mixed Script.
Let it keep learning from random internet posts, Im sure it will get better that way.
I have had it for 5 months and I am about to cancel.
Research linked in the tweet (direct quotes, page 6) claims that for "GPT-4, the percentage of generations that are directly executable dropped from 52.0% in March to 10.0% in June. " because "they added extra triple quotes before and after the code snippet, rendering the code not executable." so I wouldn't listen to this particular paper too much. But yeah OpenAI tinkers with their models, probably trying to run it for cheaper and that results in these changes. They do have versioning but old versions are deprecated and removed often so what could you do?
One theory that I've not seen mentioned here is that there's been a lot of work based around multiple LLMs in communication. Of these were used in the RL loop we could see similar degradatory effects as those that have recently been in the news with regards to image generation models.
For my programming needs, I seem to notice it takes wild guesses from 3rd party libraries that are private and assumes it could be used in my code. Head scratching results.
It will just make up 3rd party libraries. This seems to happen more often the less common the programming language is, like it will make up a library in that language that has the same name as actual library in Python.
I have seen that as well.
I can't tell if AI is going to become the biggest leap forward in technology that we've ever seen. Or if it's all just one giant fucking bubble. Similar to the crypto craze. It's really hard to tell and I could see it going either way.
The crypto craze was only hyped by scammers who profited from it by turning it into a get rich quick scheme. I still have not seen a legit use case for crypto. Other payment methods are faster, traceable and under some sort of financial regulation, so the exchange owner won't disappear into the night with the savings of all of his customers...
There is plenty of AI that is already in use (for example in medical diagnostics and engeneering) so we can safely say that it isn't "one giant bubble" - it might be overhyped when it comes to certain aspects like the ability to write a coherent and creative book that would have success on the market.
It can certainly help to write a book, though. So even if we aren't close to being able to just tell ChatGPT-n "write a satisfying conclusion to the Song of Ice and Fire series for me please" it's still going to shake things up quite a bit.
People seem to think that ChatGPT is way more useful than it actualy is. It's very odd.
People often take works of fiction to be akin to documentaries, so they may be expecting science fiction style AI.
The Internet was a massive success, however 95% of web companies went bankrupt during the dot com bubble. Just because something is useful doesnt' mean it can't be massively overhyped and a bubble............
I have no disagreement about that. I only wanted to convey that not 100% of it is a bubble.
It's definitely both unfortunately and I don't think journalists even sort of have the capacity to recognize that.
Well, naturally. Wait to see what happens when it reaches puberty.
Lol, lmao even
Nitter link.
As it should be.
I'd prefer Google Bard, the answers are more reliable and accurate than GPT
I guess there is an advantage in restricted/limited answers.
Hah, get fucked OpenAI.
Good riddance to the new fad. AI comes back as an investment boom every few decades, then the fad dies and they move onto something else while all the ai companies die without the investor interest. Same will happen again, thankfully.
This is a wildly incorrect assessment of the situation. If you think AI is going anywhere you're delusional. The current iteration of ai tools blow any of the tools from just a year ago out of the the water, let alone tools from a decade ago.
Yeah, calling the new developments a "fad" is wildly inaccurate.
The only reason it became hyped is due to their surprising capabilities, taking even technically oriented people by surprise at what they can do.
AI has come and gone 4 times in the past. Every single time they have been investment bubbles that followed the same cycle and this one is no different. The investment money dries up and then everyone stops talking about it until the next time.
It's like people have absolutely no memory. This exact same shit happened in the 1980s and at the turn of the millenium.
The second that investors get burned with it the money dries up. The "if you think it's going anywhere" shit is the same nonsense that gets said in every investment bubble, the most recent amusing one was esports people enthusiastically believing that esports wasn't going to shrink the moment investors got bored.
All this shit relies on investment and as soon as they move on it drops off a cliff. The only ai content worth paying attention to is the government funded work because it will survive when the bubble pops.
This is a bubble that will pop, no doubt about that, but it also is a huge step forward in practical, usable, AI systems. Both are true. LLMs have very hard limits right now, and unless someone radically changes them, they will keep those limits, but even within the limits they are useful. They aren't going to displace most of the work force, they aren't going to break the stock market, they aren't going to destroy humanity, but they are a very useful tool.
Practical and usable? lol
The only thing they're succeeding at doing is getting bazinga brained CEOs to sack half their staff in favour of exceptionally poor quality machine learning systems being pushed on people under the investment buzzphrase "AI".
90% of these companies will disappear completely when the bubble bursts. All the "real practical usable" systems will disappear because there's no market for them outside of convincing bazinga brained idiots with too much money to part with their cash.
The entire thing is not driven by any sustainable business models. None of these companies make profit. All of them will cease to exist when the bubble bursts and they can no longer sustain themselves on investment bazinga brains. The only sustainable business model I have seen that uses AI (machine learning) is the replacement of online moderation with it, which the social media companies reddit, facebook and tiktok among others are all actually paying a fortune for while laying off all human moderation. Ironically it has a roughly 50% error rate which is garbage and just allows fascist shit to run rampant online but hey ho I've almost given up entirely on the idea that fascism won't take over the west.
I use an LLM frequently in my work. It is for things that I used to Google, like PowerShell functions and where settings are in common products. That's a practical, real world use. I already said I agree that it is a bubble that will pop, but we don't need it to be profitable for other people. In my case I'm using a Llama variant locally, so every AI company out there could implode tomorrow and I'd still have the tool.
Bullshit.